时间:2022-06-14 15:03
人气:
作者:admin
最近AMD的喜事不断,关注CPU架构和超算的朋友的应该知道在中国缺席的情况下,在ISC2022 上,美国的超算Frontier成为榜首,而且由AMD+HPE+Cray打造更多的E级的集群会陆续建成。苏妈宣称的High Performance Computing的确是大势所趋。
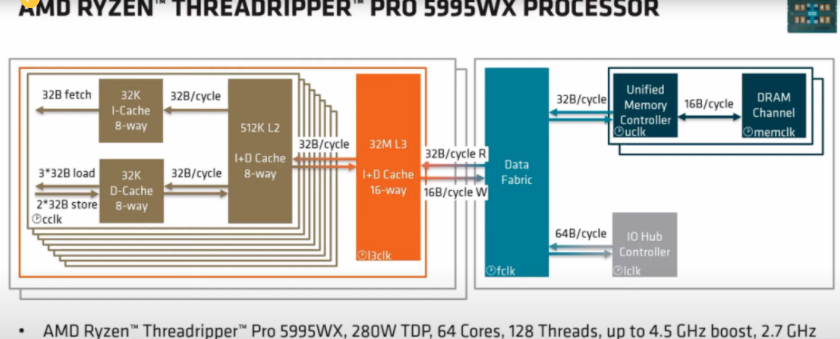
在上周的AMD 的FAD2022 中,继续放出了很多大招。其中让我比较关注的就是IF的演进和迭代。IF是AMD chip let的核心。从最初的CPU 的MCM之间的互联和chip2chip 的互联,终于跨出了和CPU/GPU的互联,以及GPU之间的互联。
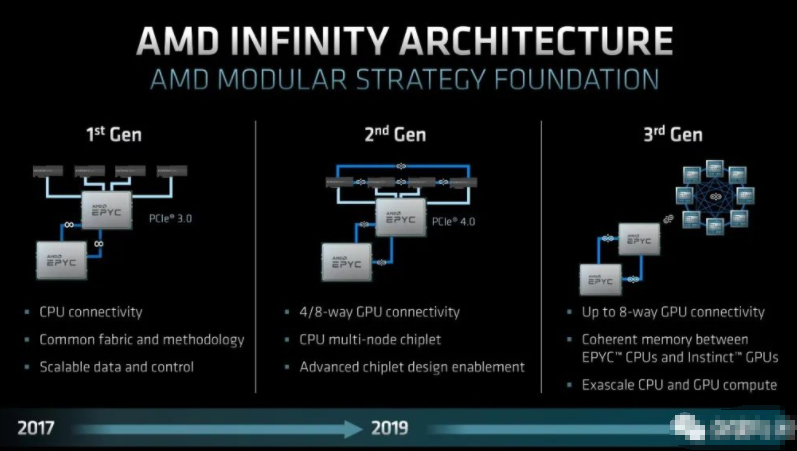
特别是第三代,妥妥的是NV-Link的初级版本,NV-Link都有了,NV-Switch还远吗,果然4代出现了。

4代的确不同凡响,AMD的GPU计算和游戏核心,Xilinx的AIE以及FPGA都可以连接。而且支持CXL2.0 的memory pool和系统级别的cache coherency。这个和最初的IF的差别已经很大了,在最初的IF中实现了两个不同的数据路径,SDF由MCM Die之间和Chip2Chip之间的。
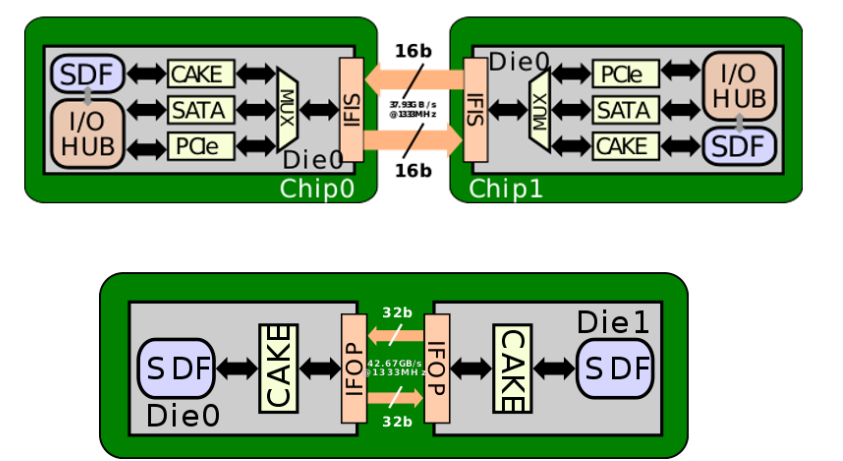
其中比较有意思的是使用CAKE(Coherent AMD socKet Extender ) 对于本地的SDF的情况进行编码,使用128-bit的serdes接口。作为MCM之间互联的接口,CAKE一直和memory 控制器跑在相同的时钟域。但是在加入更多的计算单元,特别是FPGA之后,这个时钟区域不会像之前那么简单了。但是没关系,一切于3D-VCache为中心,对于数据分析界的尼古拉斯。赵四同学来讲,如果一片64M的3D-VCach不能解决问题,来一个128M的就好。

AMD已有的HBM和3D Cache的封装技术,相对于Micro Bump省省省。等一下,这个Micro Bump不是当年Xilinx的多Die器件的成本的大头吗?

这个,有点意思,事情可能有一些变化了。AMD目前对于集成AIE (其实就是Xilinx做的AI 加速的ASIC)和GPU都公开宣布了,如何集成一个SLR, 这个有意思了。

到这里,按俺的风格,就需要开始考古了。IF的公开资料不多,主要的信息都在Papermaster的2017年的公开信息中。一个是控制路径,一个数据路径。使用这个分离的主要目的其实和它的祖先HT的目的有点不同了,控制和数据分开的好处对于软件是明显的,但是硬件里面这么搞,很好奇它能走到NV-Switch的路上去。

另一个千年的老问题,就是NUMA的影响。对于IF来讲,memory 和interconnection的协议相同,但是速率不同。NUMA有影响,但是有了庞大的3D cache,大家都虽然慢,但是我的cache大。
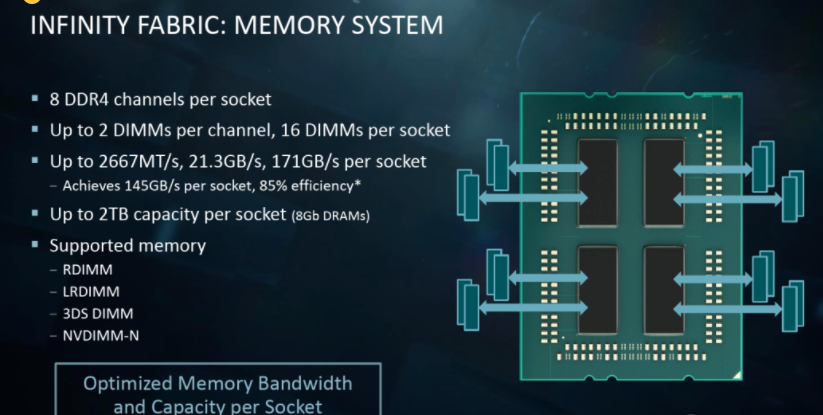

对于SDF的CC,的确有一些有意思的用法。

AMD推荐了两种refill的策略。


这个收益的确不错,毕竟AMD的cache latency 不会随着size增加而缩小。
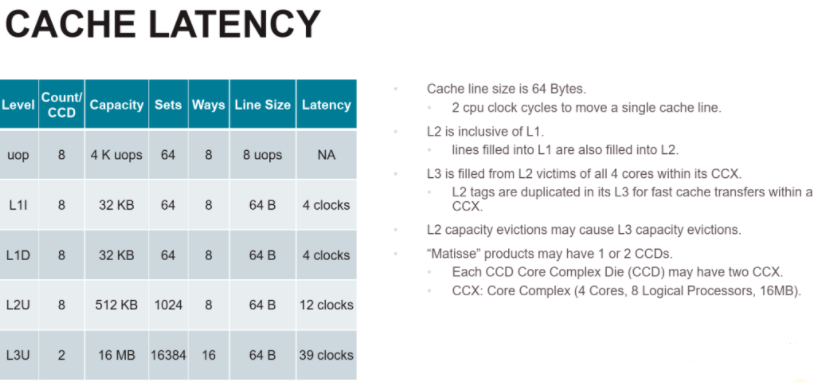
从AMD的DataFlow 来看,更能说明问题。随着Core 的密度和memclk的提升。这个到了考验Data Farbic的时候。
今天传出的一个消息,NV终于在自己的DGX中选用了Intel的蓝宝石,替代了之前2代的AMD 的CPU。NV的理由是在乎单线程的性能,虽然Intel的core不多,但是对称的4 Die方案对于latency的优势应该是明显的。当然,有人会理解成为NV怕AMD的GPU的竞争了,说实在的,在A100出来的2年之后,到现在都没有一个可以一打的对手,H100是在AI领域孤独求败呀。只能说,“同学,你想多了。”
下一篇:FPGA也能片上调试吗?

Fidus Sidewinder-100集成PCIe NVMe 控制系统,有
 关注微信
关注微信