时间:2022-04-27 12:42
人气:
作者:admin
流水线
这里先用通俗易懂的语言描述一下流水线设计思想。假设小A要从成都到哈尔滨旅游,如果直接坐火车过去恐怕要累得受不了;如果在旅程中间加几站,比如到西安、北京、天津找个客栈休息一下,路上就更加精力充沛了。
对于信号而言也是一样,加入一个状态为1的信号x需要从寄存器A传输到寄存器B,这条路线上只有组合逻辑(没有休息的地方),那么x必须保证在路上的时间保持1不变,如果传到一半值变为0了那就出错了。所以,A到B的延时就决定了系统的工作频率不能高于多少(否则会出错),系统的最大工作频率也是由最长路径上的延时决定的。
但是,假设在A到B这条路上,增加几个寄存器(信号休息的“客栈”),相当于将路径拆分为几段,信号x就不必再害怕丢失状态。缩短了路径,也就缩短了延时,也就提高了系统可以工作的最高频率。这个过程就称作“设计流水线化”。
无流水的FIR滤波器设计
1.搭建模型
《FPGA数字信号处理系列》中详细讨论过各种FIR滤波器的实现方法。本设计采用直接型FIR滤波器,并行结构,在Simulink中添加block按下图连接:
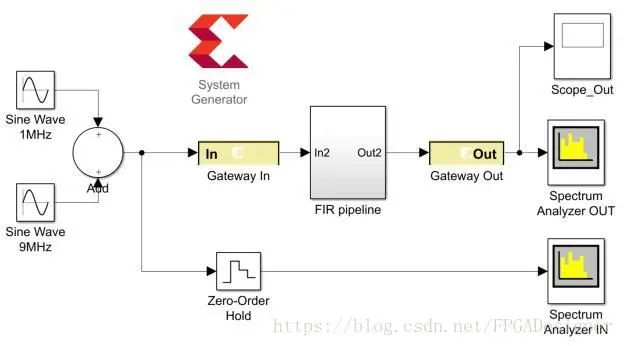
上面的设计与本系列第2篇中的设计基本相同,除了将Digital FIR Filter替换为了自己设计的子系统。子系统设计方法如下:先按照直接型FIR结构连接好各个block(如下图),将所有的block选中,点击Simulink工具栏的Diagram->Subsystem&Model Reference->Create subsystem from selection。

滤波器系数与本系列第2篇中相同,系统设置20MHz采样率,1.5MHz通带截止频率、8.5MHz阻带截止频率,对1MHz+9MHz的叠加信号滤波。上图中所有加法器(AddSub)和乘法器(Mult)中的Latency都为0,即纯组合逻辑。
为了System Generator在时序分析时检测到整个系统的时序,在FIR滤波器的输入和输出部分增加了一个Delay单元(在HDL模型中相当于寄存器)。
2.仿真验证与时序分析
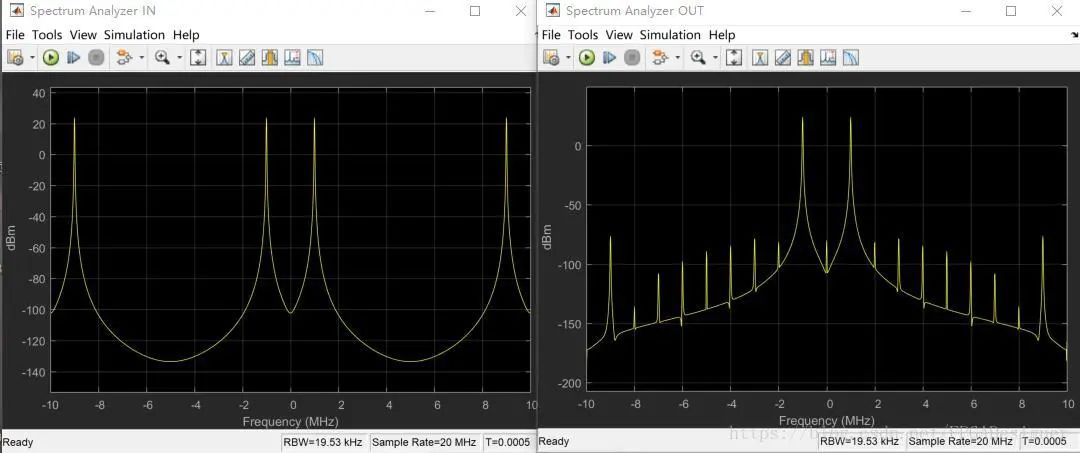
运行仿真,滤波前后频谱结果如下,与第2篇中基本相同,滤除了9Mhz的频率分量,只留下了1MHz的正弦波信号:
点击System Generator block中的Generate,运行时序分析:
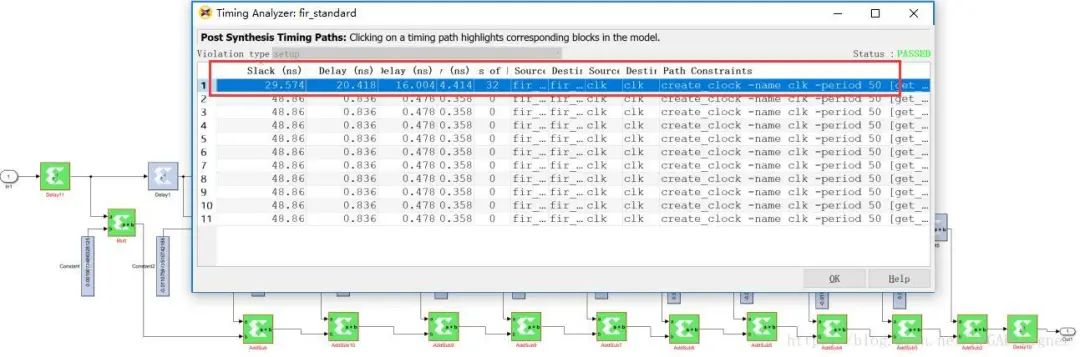
可以看到整个设计中最长的路径包含了1个乘法器和10个加法器,即直接从滤波器的输入到数据,线路延时有20.418ns,即系统最高运行频率不到50Mhz。
加法器流水线化
1.搭建模型
接下来将该设计流水线处理,来提高系统的运行速度。首先将加法器流水线化,有两种方法可以选择:1.在加法器之间加入Delay模块;2.将加法器的Latency设置为1,即一级流水。本设计采用更方便的第2中方法,修改子系统按下图连接:

Vivado中绝大多数IP核都是可以流水线化的,通过设置Latency实现。需要清楚的是,当加法器的输出有延时之后(需要计算时间),加法器同抽头延时链之间的数据就不同步了,必须做如下修改:
加法器增加了一级延时,抽头延时链相应也要多增加一级延时,即将Delay模块的Latency设置为2;
FIR结构中在第一个乘法器的输出部分省略了一个加法器(相当于第一个乘法器的结果+0),因此为了数据同步需要增加一个延迟为1的delay block。
2.时序分析
运行仿真,结果与上面相同,表明设计正确。再次点击System Generator block中的Generate,重新导出设计并运行时序分析:
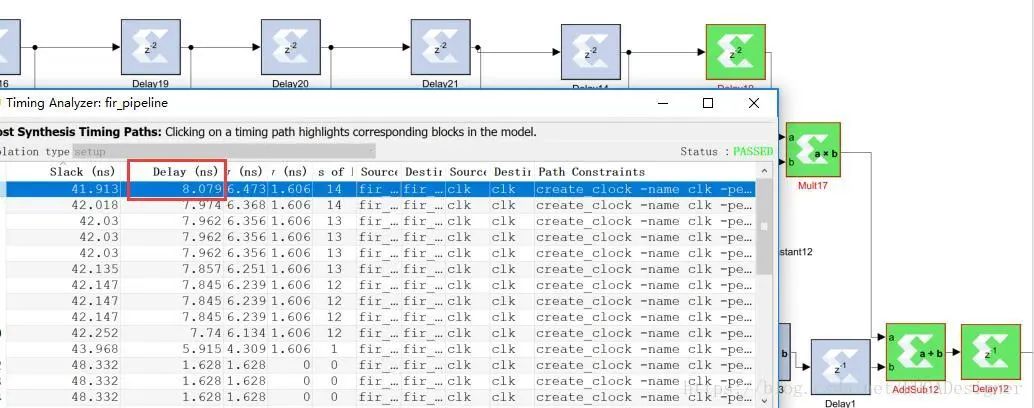
我们可以看到,在加法器流水线化之后(相当于加法器的输出结果会用一级寄存器缓存),整个设计中的最长路径变为了最后的1个乘法器+1个加法器,该路径延时降低为了8.079ns,相当于系统最高频率提升到了大约125Mhz,比上一个设计提高了2倍多。
乘法器流水线化
1.搭建模型
既然上一个设计中的最长路径中包含一个纯组合逻辑的乘法器,那我们就把乘法器也流水线化,再把路径做进一步拆分好了。将乘法器的Latency设置为3(表示三级流水),子系统连接图为:
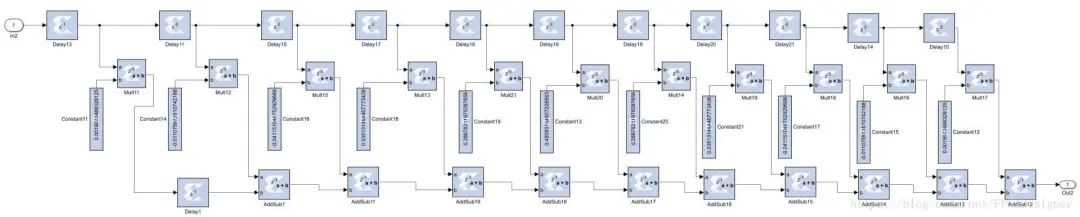
2.时序分析
运行仿真,结果与上面相同,表明设计正确。再次点击System Generator block中的Generate,重新导出设计并运行时序分析:
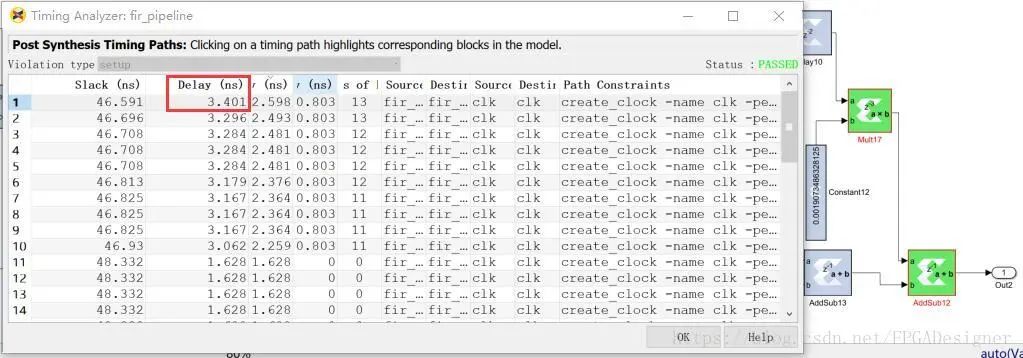
我们可以看到,在乘法器三级流水线化之后(相当于在计算乘法的整个过程中插入了三级寄存器作为缓存),整个设计中的最长路径变为了乘法器的输出到加法器这一段(不包含乘法运算),该路径延时降低为了3.401ns,相当于系统最高频率提升到了大约294Mhz,比最初的设计已经提高了大约6倍。
最后
总而言之,流水线化就是拆分组合逻辑路径,在路径中插入寄存器缓存中间结果的过程。当一个设计不满足我们期望的工作频率时,就需要从其延时最长的路径开始分析,将路径划分为多段,中间插入寄存器缓存。当然,流水线化会增加额外的资源消耗,选择“面积”还是选择“速度”正是设计者需要作出的考量。
原文标题:FPGA学习-流水线设计方法详解
文章出处:【微信公众号:FPGA设计论坛】欢迎添加关注!文章转载请注明出处。
审核编辑:汤梓红
上一篇:如何实现FPGA中的除法运算
下一篇:PLC可编程逻辑控制器的简单介绍

Fidus Sidewinder-100集成PCIe NVMe 控制系统,有
 关注微信
关注微信