时间:2023-06-16 16:47
人气:
作者:admin
01 一、前言
“分割一切,大家一起失业!”——近期,这样一句话在社交媒体上大火!这讲的就是Segment Anything Model(简称 “SAM” )。SAM 到底是什么?它具备哪些功能?它真的有这么强大吗?让我们一起通过本文了解详情!
SAM 是一个由 Meta AI 实验室推出的强大人工智能图像分割应用,可以自动识别哪些图像像素属于一个对象,并且对图像中各个对象进行自动风格处理,可广泛用于分析科学图像、编辑照片等。
SAM 的完整应用由一个图片编码器模型(encoder)以及掩码解码(mask decoder) + 提示编码模型(prompt encoder)构成,这两部分都可以被解析为独立的静态模型。其中大部分的算力负载和推理延时都集中在图片编码器任务,因此如果进一步提升图片编码器部分的执行效率,就成为了 SAM 应用的主要优化方向之一。
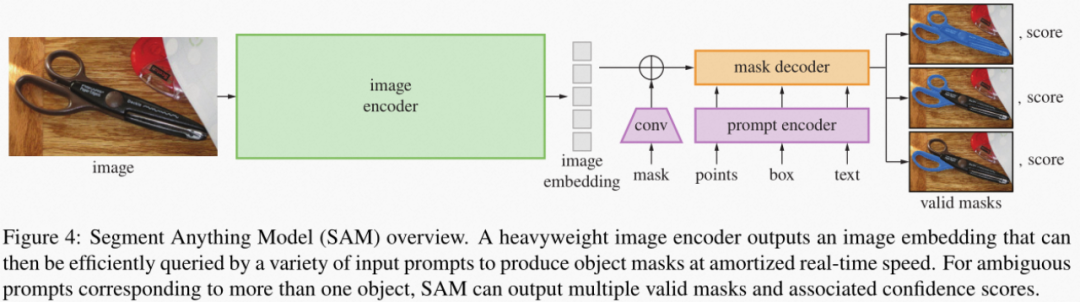
图:SAM 模型任务pipeline
本次分享讲重点演示如何通过 OpenVINO 的 NNCF 模型压缩工具实现对 SAM 编码器部分的量化压缩,实现在 CPU 侧的性能提升。
02 量化介绍
在正式开始实战之前,我们不得不提一下量化的概念,量化是指在不改变模型结构的情况下,将模型参数的表达区间从 FP32 映射到 INT8 或是 INT4 范围,用更小数值位宽来表示相同的信息,实现对于模型体积的压缩,降低内存消耗,同时在模型网络的执行过程中,系统会自动调用硬件平台专门针对低比特数据优化的指令集或 kernel 函数,提升性能。
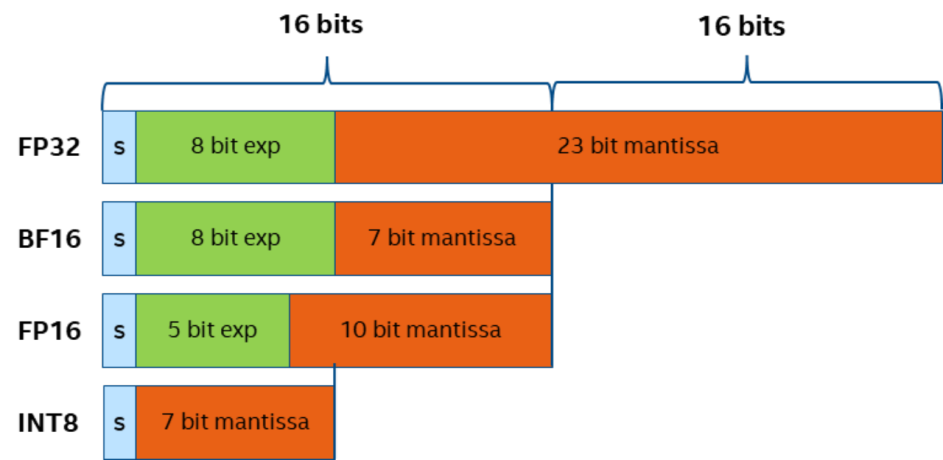
图:不同精度数据的表示位宽
Intel AVX512 VNNI 扩展指令集实现了将原本需要3个时钟周期才能完成的INT8矩阵点乘与加法运算压缩到一个时钟周期,而在最新的 AMX 指令集更是将多个 VNNI 模块进行堆叠实现了单周期内成倍的性能提升。
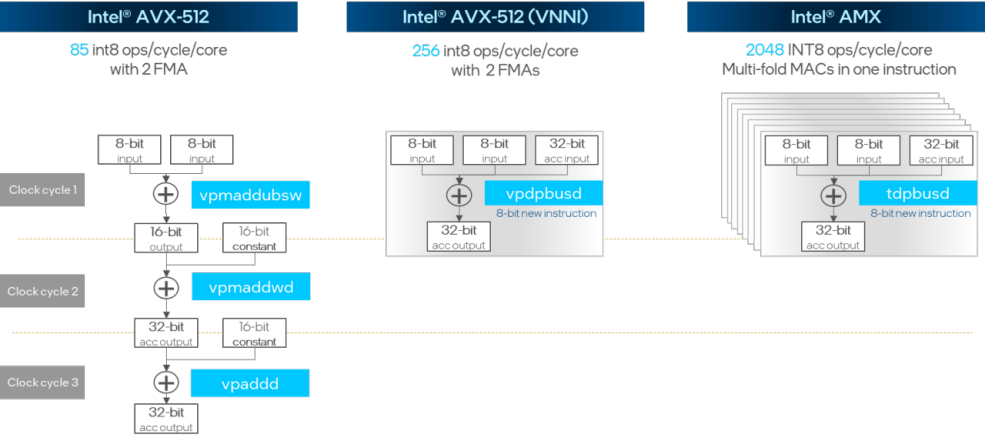
图:INT8 矩阵点乘与加法运算指令集优化
03 NNCF 训练后量化模式
NNCF 工具的全称是 Neural Network Compression Framework,是 OpenVINO 工具链中专门用于模型压缩加速的方案实现,包含量化,剪枝,二值化等多种模型压缩算法,调用方式又可以分化为训练后量化 (PTQ) 和 训练时压缩 (QAT) 两种模式,训练时压缩要需要引入原始的训练脚本和数据集,而训练后量化则可以直接针对训练生成模型文件进行压缩,无需额外的训练脚本和标注数据集参与,这也是 NNCF 在 OpenVINO 2023.0 正式发布的新功能特性, 而这个模式也仅仅需要以下两步便可实现:
1.准备校验数据集,这里的校验数据仅用作量化过程中对数据表示范围与分布的计算,因此不需要额外的标签数据,例如在图像识别任务中,我们仅需要送入200-300张左右的图片文件即可。此外我们还需要定义 DataLoader 对象与 transform_fn 数据转换函数, DataLoader 用于读取校验数据集中的每一个元素,transform_fn 用于将读取的元素转化为 OpenVINO 模型推理的直接输入数据。
import nncf
calibration_loader = torch.utils.data.DataLoader(...)
def transform_fn(data_item):
images, _ = data_item
return images
calibration_dataset = nncf.Dataset(calibration_loader,transform_fn)
2.运行模型量化,首先需要导入模型对象,然后通过 nncf.quantize() 接口,将模型对象与校验数据集绑定开启量化任务, NNCF 工具可以支持多种模型对象类型,包含openvino.runtime.Model, torch.nn.Module, onnx.ModelProto以及 tensorflow.Module
model = ... #OpenVINO/ONNX/PyTorch/TF object
quantized_model = nncf.quantize(model, calibration_dataset)
3.(可选)准确性控制模式,如果发现 NNCF 在默认模式下的导出的模型准确性下降超过预期,我们也可以使用准确性控制模式(accuracy control)完成训练后量化,此时我们需要加入带标签的测试集数据,用来评估模型在量化过程中哪些 layer 对模型准确性损失的影响(敏感度)比较大,并作为排序依据,依次将这些 layer 回退至原始精度,直到模型符合预期准确性表现。通过这个模式,我们可以在保证模型准确性的情况下,尽可能压缩模型体积,实现性能和准确性之间的平衡。具体方法可以参考以下链接:
https://docs.openvino.ai/nightly/quantization_w_accuracy_control.html
04 Segment Anything + NNCF实战
接下来让我们具体一步步看下如何使用 NNCF 的 PTQ 模式完成 SAM encoder 的量化。
1.定义数据加载器
本示例使用 coco128 作为校验数据集,其中包含 128 张 .jpg 格式的图片。由于在量化 ONNX 或 IR 静态模型的情况下,数据加载器必须是一个 torch 的 DataLoader 类,因此这里我们需要继承 torch.utils.data.Dataset 并重新构建一个数据集类,其中必须包含__getitem__方法,用于遍历数据集中的每一个对象,__len__用于获取数据集的对象数量,最后再通过 torch.utils.data.DataLoader 方法生成数据加载器。
classCOCOLoader(data.Dataset):
def__init__(self, images_path):
self.images =list(Path(images_path).iterdir())
def__getitem__(self, index):
image_path =self.images[index]
image =cv2.imread(str(image_path))
image =cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
returnimage
def__len__(self):
returnlen(self.images)
coco_dataset =COCOLoader(OUT_DIR /'coco128/images/train2017')
calibration_loader =torch.utils.data.DataLoader(coco_dataset)
2.定义数据格式转化模块
下一步是定义数据转化模块,我们可以调用之前定义 preprocess_image 函数完成数据的预处理,值得注意的是由于 calibration_loader 模块返回的单个数据对象为 torch tensor 类型 ,而 OpenVINO 的 Python 接口不支持该类型数据,我们需要先将其强制转化为 numpy 格式。
deftransform_fn(image_data):
image=image_data.numpy()
processed_image=preprocess_image(np.squeeze(image))
returnprocessed_image
calibration_dataset=nncf.Dataset(calibration_loader,transform_fn)
3.运行 NNCF 量化
为了确保量化后的模型准确性,这里我们使用原始的 FP32 ONNX 格式模型作为输入对象,而不是 FP16 的 IR 格式模型,然后再将该对象送入 nncf.quantize 接口执行量化,该函数接口中有几个比较重要的额外参数:
# Load FP32 ONNX model
model=core.read_model(onnx_encoder_path)
quantized_model=nncf.quantize(model,
calibration_dataset,
model_type=nncf.parameters.ModelType.TRANSFORMER,
preset=nncf.common.quantization.structs.QuantizationPreset.MIXED)
ov_encoder_path_int8="sam_image_encoder_int8.xml"
serialize(quantized_model,ov_encoder_path_int8)
model_type:模型类别,用于开启特殊的量化策略,例如在类 Transformer 模型中,我们需要优先保证模型的准确性。
preset:量化模式,默认为 PERFORMANCE,使用对卷积的权重和偏置均采用对称量化算法,有助于提升模型性能,此处为了提升模型准确性,我们采用 MIXED 模式,采用权重对称量化,偏置非对称量化的方法,适合模型中包含非 Relu 或者非对称的激活层。
由于 SAM encoder 模型的网络结构比较复杂,而量化过程中我们需要多次遍历模型每一个 layer 的参数,所以量化耗时相对会长一些,请大家耐心等待。这边建议使用 32G 以上内存的硬件设备,如果遇到内存不够的情况,可以通过 subset_size=100 参数,适当降低校验数据数量。
4.模型准确性比较
接下来我们比较下 INT8 和 FP16 模型的推理结果:

图:prompt 模式 FP16 – INT8 结果比较

图:auto 模式 FP16 – INT8 结果比较
可以看到在 prompt 和 auto 模式下,INT8 模型的准确性相较 FP16 模型,几乎没有任何变化。
注:auto 模式下,mask 将使用随机生成的颜色。
5.性能比较
最后我们通过 OpenVINO 自带的 benchmark_app 工具比较下性能指标:

图:Benchmark 结果 (FP16)
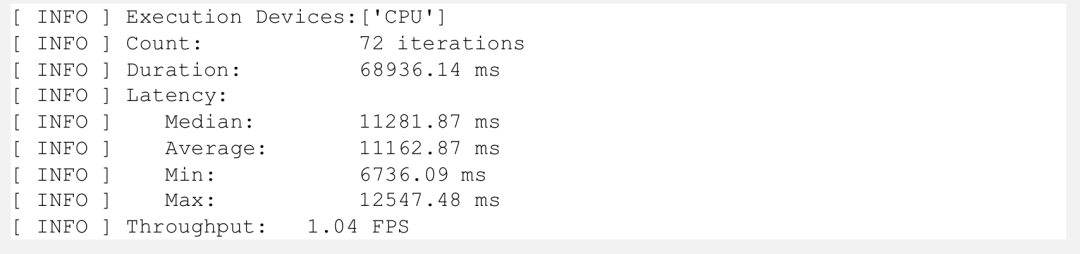
图:Benchmark 结果 (INT8)
可以看到在 CPU 端,INT8 模型相较 FP16 提升了大约 30%, 体积从原本的 350MB 压缩到了 100MB 不到。
05 总结
鉴于 SAM 出色的自动化分割能力,相信未来会有越来越多应用场景会部署这项技术,而在产业化落地的过程中,开发者往往最关注的就是性能和准确性之间的平衡,以此获取成本更优的方案。OpenVINO NNCF 工具通过对 Segment Anything encoder 部分的量化压缩,在几乎没有影响模型准确性的情况下,显著提升模型的运行效率,降低模型占用空间。
审核编辑:刘清





 关注微信
关注微信