时间:2020-03-03 10:45
人气:
作者:admin
(文章来源:半导体投资联盟)
语音识别技术是指通过计算装置的分析来识别或理解如人类发出的语音等的声学信号的技术。近年来随着基于深度学习(deep learning)的机器学习(machine learning)技术的成熟,各行各业开始纷纷引入深度学习技术来寻求实际问题的解决。
语音识别技术的第一梯队公司三星公司便率先引入深度学习技术并结合利用反映了识别对象语言的结构特性的学习数组的方法来提升使用语音识别准确性。上述方法在三星公司的新专利“语音识别方法”中被提出,其专利号(CN109215637A)。
三星公司提出的语音识别主要是提供两个方面来提升识别准确率的,第一是构建的深度神经网络声学模型,利用深度神经网络的强大的特征提取能力来获取语音数据中的语音信息。第二个是利用了反映识别对象语言的结构特性,从语音本质上出发去获取语音特征信息。接下来小编将详细的进行叙述三星公司的语音技术新方法。
该专利中提出的语音识别装置如图所示,包括学习数据获取部、目标标签构成部和声学模型构建部、语音输入部、目标标签预测部以及解码部。学习书籍获取部主要是用户获取构成目标标签的原始学习数据组如最初的语音文本。目标标签部从包含在原始学习数组中文本以反映识别对象语言的机构特性的方法构成目标标签。
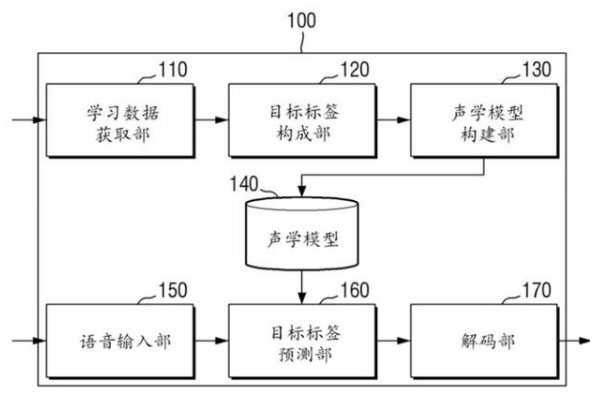
声学模型构建部主要是构建关于深度神经网络模型的声学模型,用于识别语音的输入和目标标签的预测输出。解码部主要是通过使用声学模型对输入的语音进行目标标签的预测输出,根据输出的预测来进行解码得到最终的语言文本。
该专利中最核心的部分是使用目标标签构成部来利用对象语言的机构特性。目标标签构成部120可将包含在原始学习数据组310中的文本以字母为单位进行分离并且以后述方式构成反映了识别对象语言的结构特性的四个级别的目标标签。比如说,在识别对象语言的字母自身作为一个文字使用的英语的情况下,当学习数据310a的文本为“ nice to meet you”时,学习数据330a的第一级别目标标签可由“nice$to$meet$you”构成。
在经过目标标签构成部的构造后,深度神经网络的输入端和输出端便有了结果。首先,是获取原始学习数据组,通过将包含在原始学习数据中的文本信息以字母为单位进行分离来构成目标标签,作为声学模型的输出端。声学模型的输入端便是语音数据,通过学习包含在原始学习数据中的学习用语音数据及目标标签,来训练声学模型。
三星公司中专利的语音识别技术属于改进后的端对端深度学习模型,改进的地方在于把传统的端对端的深度学习模型的语音文本输出端改成了目标标签输出端,而这目标标签输出端能很好的体现要识别的对象语言的结构特性。当然这也给整个系统带来了一定的复杂性,因为最终的声学模型的输出还需要经过一个对象语言解码端,但是该专利中的方法还是带来了语音识别技术的准确性提高。
(责任编辑:fqj)




 关注微信
关注微信