时间:2019-08-26 16:12
人气:
作者:admin
研发出了一种简单的新型模型,该模型不仅完美地融合了声学和语音线索,而且将说话人分类和语音识别任务融合在了同一个系统中。相较于相同环境下仅仅进行语音识别的系统相比,这个集成模型并没有显著降低语音识别性能。
我们意识到,很关键的一点是:RNN-T 架构非常适用于集成声学和语言学线索。RNN-T 模型由三个不同的网络组成:(1)转录网络(或称编码器),将声帧映射到一个潜在表征上。(2)预测网络,在给定先前的目标标签的情况下,预测下一个目标标签。(3)级联网络,融合上述两个网络的输出,并在该时间步生成这组输出标签的概率分布。
请注意,在下图所示的架构中存在一个反馈循环,其中先前识别出的单词会被作为输入返回给模型,这使得 RNN-T 模型能够引入语言学线索(例如,问题的结尾)。
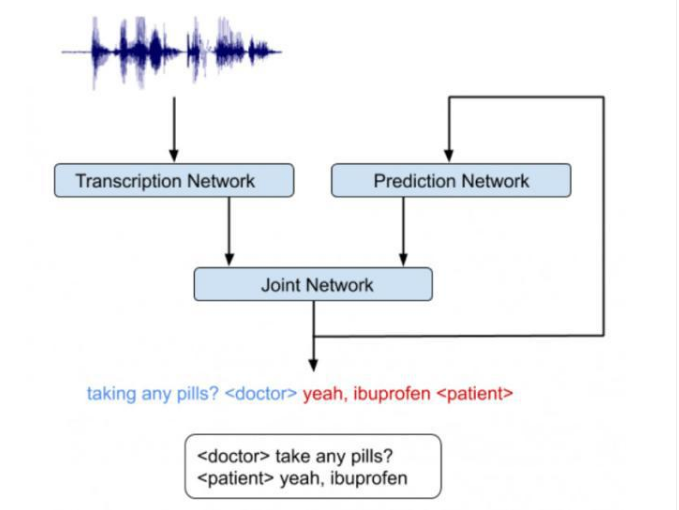
集成的语音识别和说话人分类系统示意图,该系统同时推断「谁,在何时,说了什么」
在图形处理单元(GPU)或张量处理单元(TPU)这样的加速器上训练 RNN-T 并不是一件容易的事,这是因为损失函数的计算需要运行「前向推导-反向传播」算法,该过程涉及到所有可能的输入和输出序列的对齐。最近,该问题在一种对 TPU 友好的「前向-后向」算法中得到了解决,它将该问题重新定义为一个矩阵乘法的序列。我们还利用了TensorFlow 平台中的一个高效的 RNN-T 损失的实现,这使得模型开发可以迅速地进行迭代,从而训练了一个非常深的网络。
这个集成模型可以直接像一个语音识别模型一样训练。训练使用的参考译文包含说话人所说的单词,以及紧随其后的指定说话人角色的标签。例如,「作业的截止日期是什么时候?」<学生>,「我希望你们在明天上课之前上交作业」<老师>。当模型根据音频和相应的参考译文样本训练好之后,用户可以输入对话记录,然后得到形式相似的输出结果。我们的分析说明,RNN-T 系统上的改进会影响到所有类型的误差率(包括较快的说话者转换,单词边界的切分,在存在语音覆盖的情况下错误的说话者对齐,以及较差的音频质量)。此外,相较于传统的系统,RNN-T 系统展现出了一致的性能,以每段对话的平均误差作为评价指标时,方差有明显的降低。
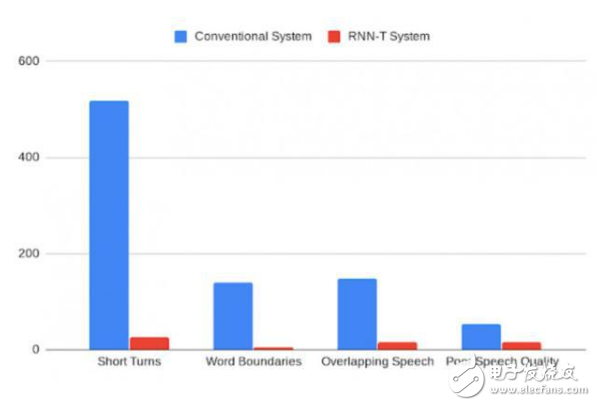
传统系统和 RNN-T 系统错误率的对比,由人类标注者进行分类。
此外,该集成模型还可以预测其它一些标签,这些标签对于生成对读者更加友好的 ASR 译文是必需的。例如,我们已经可以使用匹配好的训练数据,通过标点符号和大小写标志,提升译文质量。相较于我们之前的模型(单独训练,并作为一个 ASR 的后处理步骤),我们的输出在标点符号和大小写上的误差更小。




 关注微信
关注微信