时间:2023-08-25 11:00
人气:
作者:admin
人工智能的飞跃式发展使得人类社会对算力的需求呈指数式增长,为计算硬件发展带来了全新的挑战与机遇。光具有高并行度、低延迟、低功耗的优势,意味着其有极大的潜力来帮助加速计算、加速传输,从而提升算力,为人工智能算法带来新的可能性。曦智科技基于大规模光电混合技术的计算新范式,发展出纵向单节点以及横向多节点的算力提升解决方案。在纵向单节点算力提升方面,曦智科技提出了计算新原理——光子矩阵计算(oMAC)。
算力网络新范式
矩阵乘法运算是一种线性计算,被广泛运算于人工智能算法中,在不同算法中占比约60%至90%不等。而光非常适合用于线性计算,它的传播、干涉等行为可被视为线性运算。例如传播过程中对光幅度的连续调节可被视为乘法,双臂干涉[1]可被视为2×2的复数矩阵乘法等。通过堆叠这些基础的运算单元,我们就可实现大尺寸的光子矩阵乘法器。
在光执行计算的过程中,我们可以对光的某些维度的特征进行处理和编码,因此光能够表达个数值。同时,光学器件能够对光的数值进行调节。比如,光在经过不同介质时,通过控制介质的透射率,可以调节光在这个过程中的衰减或增强,如初始输入为1,而经过介质时衰减至0.5。通过不同的干涉和调节,光就能够完成线性计算。
光计算十分高效,计算在光传播的过程中便能完成,整个过程只需要几分之一纳秒,计算延迟极低,且对矩阵规模的增加不敏感,规模越大光的优势就越显著。同时,光执行计算任务的能耗更低。光在执行运算任务时是被动的,这个过程不需要消耗额外的能量,仅仅需要一束光源便可完成整个动作。在运算中,光器件的损耗很低,且不会发热。
此外,光在并行度方面也具有优势。光不会互相干扰,多束光能够在同一条光路里传输和计算,光的波分复用[2]技术允许不同的数在同一时刻被编码在不同的波长上进行矩阵乘运算,因此具有很高的并行度。
曦智科技光子矩阵计算处理器PACE
基于oMAC技术,曦智科技于2021年发布了光子计算处理器PACE (Photonic Arithmetic Computing Engine),(点击查看更多)其核心是64×64的光学矩阵乘法器,由一块集成硅光芯片和一块CMOS微电子芯片以3D封装形式堆叠而成。PACE的单个光子芯片中集成超过10000个光子器件,运行1GHz系统时钟,运行NP完全计算问题的速度与目前高端GPU相比显著提高,成功验证了光子计算的优越性。
注释: [1]双臂干涉:是一种光学干涉实验装置,光源发出的光线被分成两束,分别经过两条平行的路径(即双臂),然后再次汇聚在一起。当这两束光线重新合并时,它们可能会处于相位差,导致干涉现象的发生。 [2]波分复用:在同一根光纤中同时让两个或两个以上的光波长信号,通过不同光信道各自传输信息的技术,称之为波分复用技术。
审核编辑:彭菁
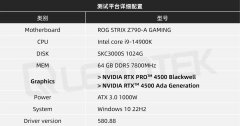
NVIDIA RTX PRO 4500 Blackwell GPU测试分析




 关注微信
关注微信