时间:2018-01-27 00:34
人气:
作者:admin
OpenAI研究人员日前发布了一个工具库,该工具库可以帮助研究人员在图形处理器(graphics-processor-unit,GPU)上建立更快、更高效、占内存更少的神经网络。
OpenAI研究人员日前发布了一个工具库,可以帮助研究人员在图形处理器上建立更快、更高效、占内存更少的神经网络。神经网络由多层相连的节点构成。这类网络的架构根据数据和应用变化很多,但是所有模型都受到它们在图形处理器上运行方式的限制。
以更少的计算能力训练更大模型的一种办法是引入稀疏矩阵。如果一个矩阵里面有很多零,那就视为稀疏矩阵。阵列中的空元素可以在矩阵乘法中压缩和跳过,就在图形处理器中占用的内存更少。进行运算的计算成本与矩阵中非零条目的数量成比例,有了稀疏矩阵就意味着节省了多的计算能力用于构建更广或更深的网络,能训练更高效,进行推断的速度可提高十倍。
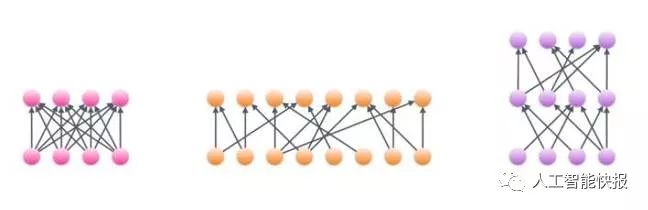
研究人员指出,英伟达并不支持块稀疏模型。所以,OpenAI的团队决定开发核——将软件汇集在硬件上运行的微程序,优化用于为更大的研究圈构建块稀疏网络。
伊隆·马斯克(Elon Musk)的人工智能研究部门的研究人员内部使用这种程序训练长的短时记忆网络,对亚马逊网(Amazon)和互联网电影资料库(IMDB)的评论文本进行情感分析。
“我们的稀疏模型将互联网电影资料库数据集文本水平的艺术状态误差从5.91%降低到5.01%。从我们以往的结果来看,这个提高很有前景,因为之前最好的结果也只是在更短句子水平的数据集运算。”OpenAI在博文中表示。
核心程序在英伟达的统一计算设备架构(CUDA)运算平台编写,OpenAI最近只开发了TensorFlow的服务运行,所以在不同框架下工作的研究人员要编写自己的服务运行,它也只支持英伟达图形处理器。OpenAI的技术人员表示:这确实可以扩展到支持小型块矩阵乘法的其他架构,包含了我知道的大多数架构,但是谷歌的TPU2不在其中。虽然结果很有前景,“但是由于这些核程序仍然很新,我们还没有确定它们能在何时何处帮助“神经网络架构”。实验中,我们提供了一些情景,它能帮助向模型增加稀疏。我们鼓励研究圈帮助进一步探索这个领域。”该研究人员表示。
英伟达知道了这项工作,正在等着代码发布,以便为其提供更广的支持,这名技术人员补充说。OpenAI的工作与麻省理工学院研究人员开发的软件Taco相似,后者产生了自动处理稀疏矩阵所需的代码。
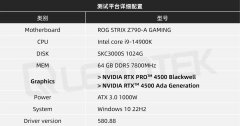
NVIDIA RTX PRO 4500 Blackwell GPU测试分析




 关注微信
关注微信