时间:2023-08-04 10:32
人气:
作者:admin
知识点离散数据的处理
若数据存在“序”关系则连续化,如:
| 离散 | 连续 |
| 高/m | 高 |
| 10 | 1 |
| 5 | 0.5 |
| 1 | 0 |
否则,转为K维向量代码可见本实例中的Pd.get_dummies(X['state'])。但要注意虚拟变量,例如“性别”变量,可虚拟出“男”和”女”两个变量,
| 男 | 1 | 0 |
| 女 | 0 | 1 |
这里所说的虚拟变量陷阱是两个或多个变量高度相关的情况,简单地说,一个变量可以从其他变量中预测出来,那么这里就有一个重复的类别,可以去掉一个变量,节约内存计算机内存空间,减少计算量。
本实例用的数据集是50_Startups.csv,
代码如下:
importnumpyasnp
pipinstallmatplotlib
importmatplotlib.pyplotasplt
importpandasaspd
dataset=pd.read_csv("D:/python/50.csv")
X=dataset.iloc[:,0:4]#0到3列的所有行数据(共4列)
X["State"].unique()
y=dataset.iloc[:,4]#第5列的所有行数据
pd.get_dummies(X['State'])#离散数据转为K维向量
statesdump=pd.get_dummies(X['State'],drop_first=True)#去掉X['State']的第一列数据(减少虚拟变量)
X=X.drop('State',axis=1)
X=pd.concat([X,statesdump],axis=1)
from sklearn.model_selection import train_test_split
x_train,x_test,y_train,y_test=train_test_split(X,y,test_size=0.3,random_state=0)
x_train
#引入线性回归模型拟合训练集
from sklearn.linear_model import LinearRegression
regressor=LinearRegression()
model=regressor.fit(x_train,y_train)
#预测测试集的结果
y_predict=regressor.predict(x_test)
from sklearn.metrics import r2_score#
score1=r2_score(y_test,y_predict)
model.coef_#多元函数的系数
model.intercept_#函数的截距
model.score(X,y)
审核编辑:刘清
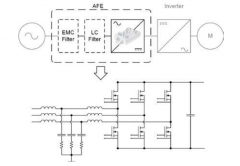
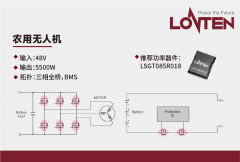
龙腾半导体SGT MOSFET LSGT085R018在智慧农业无



 关注微信
关注微信