时间:2023-05-29 15:31
人气:
作者:admin
Rust以其独特的安全性、速度和并发性组合而迅速流行。但是与其它任何语言一样,要充分利用Rust需要的不仅仅是理解它的语法和习惯用法——还需要深入了解如何有效地利用和优化它的编译器。
为了说明这一点,我们设计了一个实际用例——一个Actix Web应用程序中的矩阵乘法任务。这种cpu密集型操作为分析各种编译器优化提供了一个完美的场景。
随着实验的深入,我们将调整Cargo.toml文件的设置。利用特定的构建标志,甚至交换内存分配器。通过测量每次更改对性能的影响,我们将对Rust的编译器优化有一个全面的了解。
实际用例
我们使用Actix Web开发了一个紧凑的应用程序,具有唯一的路由/matrix-multiplication。这个接口接收一个JSON数据,带有一个属性:n。
在接收到请求后,应用程序立即开始行动,动态地生成两个大小为n x n的矩阵,在矩阵中随机填充一些数据。然后将这些矩阵相乘在一起,将计算的结果返回给用户。
新建一个Rust项目:
cargonewcompiler-optimizations然后在Cargo.toml文件中写入如下内容:
[dependencies]
anyhow="1.0.71"
actix-web="4.3.1"
dotenv="0.15.0"
serde={version="1.0",features=["derive"]}
serde_json="1.0.96"
log="0.4.17"
env_logger="0.10.0"
serde_derive="1.0.163"
rand="0.8.5"
mimalloc={version="0.1.37",default-features=false}
[profile.release]
lto=true
codegen-units=1
panic="abort"
strip=true
在src/main.rs中写入如下代码:
usestd::env;
userand::Rng;
useactix_web::{App,get,post,HttpResponse,HttpServer,middleware,web};
useanyhow::Result;
useserde::{Deserialize,Serialize};
#[global_allocator]
staticGLOBAL:mimalloc::MiMalloc=mimalloc::MiMalloc;
#[derive(Debug,Clone,Serialize,Deserialize)]
structMessage{
pubmessage:String,
}
#[derive(Debug,Clone,Serialize,Deserialize)]
structMatrixSize{
pubn:usize,
}
#[derive(Debug,Clone,Serialize,Deserialize)]
structMatrixResult{
pubmatrix:Vec>,
}
#[get("/healthz")]
asyncfnhealth()->HttpResponse{
HttpResponse::Ok().json(Message{
message:"healthy".to_string(),
})
}
asyncfnnot_found()->HttpResponse{
HttpResponse::NotFound().json(Message{
message:"notfound".to_string(),
})
}
#[post("/matrix-multiplication")]
asyncfnmatrix_multiplication(size:web::Json)->HttpResponse{
letn=size.n;
letmatrix_a=generate_random_matrix(n);
letmatrix_b=generate_random_matrix(n);
letresult=multiply_matrices(&matrix_a,&matrix_b);
HttpResponse::Ok().json(MatrixResult{matrix:result})
}
fngenerate_random_matrix(n:usize)->Vec>{
letmutrng=rand::thread_rng();
(0..n).map(|_|(0..n).map(|_|rng.gen_range(0..nasi32)).collect()).collect()
}
fnmultiply_matrices(matrix_a:&Vec>,matrix_b:&Vec>)->Vec>{
leta_rows=matrix_a.len();
leta_cols=matrix_a[0].len();
letb_cols=matrix_b[0].len();
letmutresult=vec![vec![0;b_cols];a_rows];
foriin0..a_rows{
forjin0..b_cols{
forkin0..a_cols{
result[i][j]+=matrix_a[i][k]*matrix_b[k][j];
}
}
}
result
}
#[actix_web::main]
asyncfnmain()->Result<()>{
env_logger::new().default_filter_or("info"));
letport=env::var("PORT").unwrap_or_else(|_|"8080".to_string());
HttpServer::new(move||{
App::new()
.wrap(middleware::default())
.service(health)
.service(matrix_multiplication)
.default_service(web::route().to(not_found))
})
.bind(format!("0.0.0.0:{}",port))?
.run()
.await.expect("failedtorunserver");
Ok(())
}
优化设置
1,Cargo.toml配置文件配置了-[profile.release]部分,用于调整优化性能。我们使用了以下优化设置:
lto = true:用于启用链路时间优化;
codegen-units = 1:即在整个crate中使用最高级别优化;
panic = "abort":发生panic时调用abort而不是unwind;
strip = true:通过移除debug符号来减小二进制大小。
2,构建标识——通过设置RUSTFLAGS= " -c target-cpu=native ",我们可以确保编译器根据机器的特定架构来优化构建。
3,备用内存分配器——我们还尝试了mimalloc内存分配器,对于某些工作负载,它可以提供比默认分配器更好的性能特征。
测试
为了对Actix Web API进行负载测试,我们将使用一个功能强大但轻量级的工具——Drill。
为了模拟高负载,我们的测试参数将包括两个场景中的500个并发请求——一个有10,000次迭代,另一个有20,000次迭代。这实际上分别达到了50,000和100,000个请求。
测试将在各种配置下进行,以获得全面的性能视图,如下所列:
1,cargo run :构建一个没有任何优化的开发版本(标记为“D”)。
2,cargo run --release:构建一个没有任何优化的发布版本(标记为“R”)。
3,RUSTFLAGS="-C target-cpu=native" cargo run --release:根据机器的特定架构来优化构建一个发布版本,(标记为“ROpt”)。
4,与上一个命令一样,但是在代码中采用了MimAlloc的内存分配器(表示为'ROptMimAlloc')。
结果
|BuildType|TotalTime(s)|Requestspersecond| |---|---|---| |DevBuildUnoptimized50k|71.3|701.45| |ReleaseBuildUnoptimized50k|27.0|1849.95| |ReleaseBuildOptimized(flags)50k|25.8|1937.80| |ReleaseBuildOptimized(flags+mimalloc)50k|26.7|1873.65| |ReleaseBuildUnoptimized100k|52.1|1918.27| |ReleaseBuildOptimized(flags)100k|51.7|1934.59| |ReleaseBuildOptimized(flags+mimalloc)100k|51.1|1955.07|
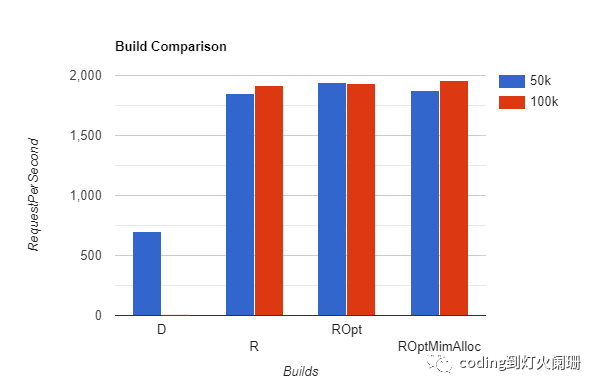
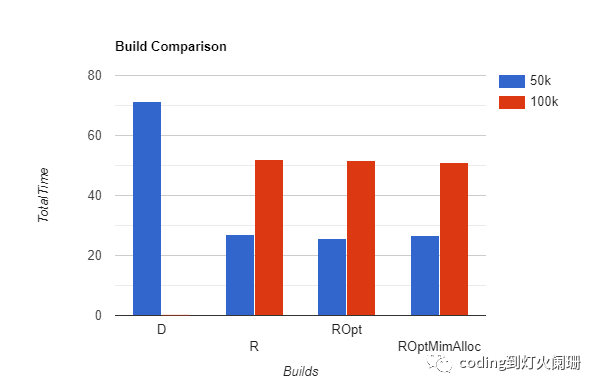
从50k请求测试开始,未优化的开发构建每秒能够处理大约701.45个请求,但是当代码在发布模式下编译时,每秒的请求飙升到1849.95个。这展示了Rust编译器在从开发模式切换到发布模式时所产生的显著差异。
使用针对本机CPU架构的构建标志添加优化,进一步提高了性能,达到每秒1937.80个请求。
当我们加入mimalloc(备用内存分配器)时,每秒请求数略微下降到1873.65。这表明,虽然mimalloc可以提高内存使用效率,但它不一定能在每个场景中都能提高请求处理速度。
转到100k个请求测试,有趣的是,未优化版本和优化版本之间的性能差异不那么明显。未优化的版本实现了每秒1918.27个请求,而优化的版本(带和不带mimalloc)分别达到了每秒1934.59和1955.07个请求。
这表明,当处理大量请求时,我们优化的影响变得不那么明显。尽管如此,即使在更重的负载下,构建优化仍然能提供最佳性能。
原作者:刘清






 关注微信
关注微信