时间:2023-05-12 09:57
人气:
作者:admin
在这篇博文中,我们介绍了一种全新的 LlamaIndex 数据结构:文档摘要索引。我们描述了与传统语义搜索相比,它如何帮助提供更好的检索性能,并通过一个示例进行了介绍。
1背景
大型语言模型 (LLM) 的核心场景之一是对用户自己的数据进行问答。为此,我们将 LLM 与“检索”模型配对,该模型可以对知识语料库执行信息检索,并使用 LLM 对检索到的文本执行响应合成。这个整体框架称为检索增强生成。
今天大多数构建 LLM 支持的 QA 系统的用户倾向于执行以下某种形式的操作:
由于各种原因,这种方法提供了有限的检索性能。
现有方法的局限性
使用文本块进行嵌入检索有一些限制。
添加关键字过滤器是增强检索结果的一种方法。但这也带来了一系列挑战。我们需要手动或通过 NLP 关键字提取/主题标记模型为每个文档充分确定合适的关键字。此外,我们还需要从查询中充分推断出正确的关键字。
文档摘要索引
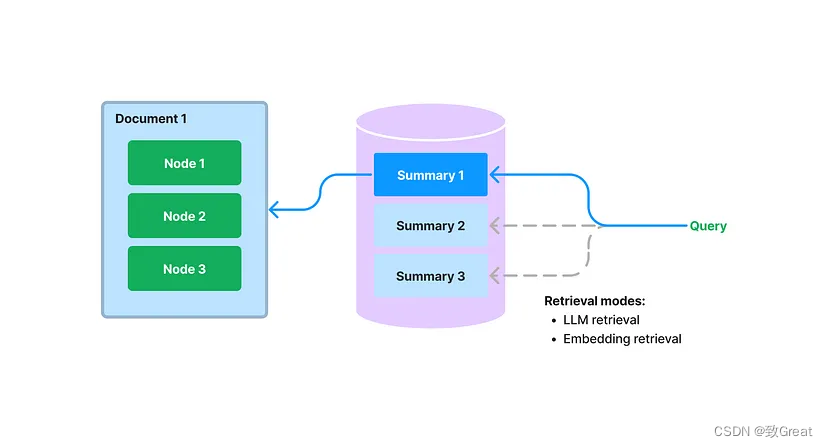
在LlamaIndex中提出了一个新索引,它将为每个文档提取/索引非结构化文本摘要。该索引可以帮助提高检索性能,超越现有的检索方法。它有助于索引比单个文本块更多的信息,并且比关键字标签具有更多的语义。它还允许更灵活的检索形式:我们可以同时进行 LLM 检索和基于嵌入的检索。
怎么运行的
在构建期间,我们提取每个文档,并使用 LLM 从每个文档中提取摘要。我们还将文档拆分为文本块(节点)。摘要和节点都存储在我们的文档存储抽象中。我们维护从摘要到源文档/节点的映射。
在查询期间,我们使用以下方法根据摘要检索相关文档以进行查询:
请注意,这种检索文档摘要的方法(即使使用基于嵌入的方法)不同于基于嵌入的文本块检索。文档摘要索引的检索类检索任何选定文档的所有节点,而不是返回节点级别的相关块。
存储文档的摘要还可以实现基于 LLM 的检索。我们可以先让 LLM 检查简明的文档摘要,看看它是否与查询相关,而不是一开始就将整个文档提供给 LLM。这利用了 LLM 的推理能力,它比基于嵌入的查找更先进,但避免了将整个文档提供给 LLM 的成本/延迟
想法
带有摘要的文档检索可以被认为是语义搜索和所有文档的强力摘要之间的“中间地带”。我们根据与给定查询的摘要相关性查找文档,然后返回与检索到的文档对应的所有节点。
我们为什么要这样做?通过在文档级别检索上下文,这种检索方法为用户提供了比文本块上的 top-k 更多的上下文。但是,它也是一种比主题建模更灵活/自动化的方法;不再担心自己的文本是否有正确的关键字标签!
例子
让我们来看一个展示文档摘要索引的示例,其中包含关于不同城市的维基百科文章。
本指南的其余部分展示了相关的代码片段。您可以在此处找到完整的演练(这是笔记本链接)。
我们可以构建GPTDocumentSummaryIndex一组文档,并传入一个ResponseSynthesizer对象来合成文档的摘要。
from llama_index import(
SimpleDirectoryReader,
LLMPredictor,
ServiceContext,
ResponseSynthesizer
)
from llama_index.indices.document_summary import GPTDocumentSummaryIndex
from langchain.chat_models import ChatOpenAI
#load docs,define service context
...
#build the index
response_synthesizer=ResponseSynthesizer.from_args(response_mode="tree_summarize",use_async=True)
doc_summary_index=GPTDocumentSummaryIndex.from_documents(
city_docs,
service_context=service_context,
response_synthesizer=response_synthesizer
)
建立索引后,我们可以获得任何给定文档的摘要:
summary=doc_summary_index.get_document_summary("Boston")
接下来,我们来看一个基于 LLM 的索引检索示例。
from llama_index.indices.document_summary import DocumentSummaryIndexRetriever
retriever=DocumentSummaryIndexRetriever(
doc_summary_index,
#choice_select_prompt=choice_select_prompt,
#choice_batch_size=choice_batch_size,
#format_node_batch_fn=format_node_batch_fn,
#parse_choice_select_answer_fn=parse_choice_select_answer_fn,
#service_context=service_context
)
retrieved_nodes=retriever.retrieve("What are the sports teams in Toronto?")
print(retrieved_nodes[0].score)
print(retrieved_nodes[0].node.get_text())The retriever will retrieve asetof relevant nodesfora given index.`
请注意,除了文档文本之外,LLM 还返回相关性分数:
8.0
Toronto((listen)tə-RON-toh;locally[təˈɹɒɾ̃ə]or[ˈtɹɒɾ̃ə])is the capital city of the Canadian province of Ontario.With a recorded population of 2,794,356in2021,it is the most populous cityinCanada...
query_engine=doc_summary_index.as_query_engine(
response_mode="tree_summarize",use_async=True
)
response=query_engine.query("What are the sports teams in Toronto?")
print(response)
#use retriever as part of a query engine
from llama_index.query_engine import RetrieverQueryEngine
#configure response synthesizer
response_synthesizer=ResponseSynthesizer.from_args()
#assemble query engine
query_engine=RetrieverQueryEngine(
retriever=retriever,
response_synthesizer=response_synthesizer,
)
#query
response=query_engine.query("What are the sports teams in Toronto?")
print(response)
审核编辑 :李倩






 关注微信
关注微信