时间:2023-02-20 10:11
人气:
作者:admin
我们介绍一篇2022 CVPR Oral的三维场景重建论文:Neural 3D Scene Reconstruction with the Manhattan-world Assumption,该论文由浙江大学CAD&CG国家重点实验室/浙大-商汤三维视觉联合实验室提出。

论文链接:https://arxiv.org/abs/2205.02836
论文代码:https://github.com/zju3dv/manhattan_sdf
Project page:https://zju3dv.github.io/manhattan_sdf/
1. 引言
1.1 论文的问题描述
输入在室内场景采集的图像序列,论文希望能生成该室内场景的三维模型。该问题有许多应用,例如虚拟与增强现实、机器人等。

1.2 当前方法在这个问题的局限性
传统方法一般通过MVS(Multi-View Stereo) [1,2] 做场景重建,首先根据多视角匹配来估计每个视角的深度图,然后将每个视角的深度在三维空间中做融合。这类方法最大的问题在于难以处理弱纹理区域、非朗伯表面,原因是这些区域难以做匹配,从而导致重建不完整。
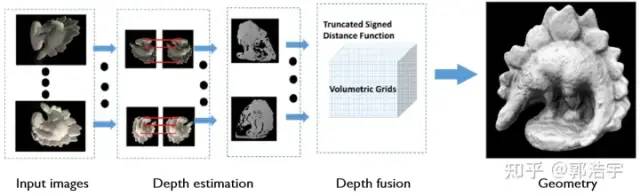
Multi-view Stereo via Depth Map Fusion: A Coordinate Decent Optimization Method
最近,有方法提出基于隐式神经表示做三维重建。NeRF [3] 通过可微分的体积渲染技术从图像中学习隐式辐射场。NeRF可以实现有真实感的视角合成,但是几何重建结果噪音很严重,主要是因为缺乏表面约束。NeuS [4] 和 VolSDF [5] 使用有SDF(向距离场)建模场景的几何,并实现了基于SDF的体积渲染,可以得到相比于NeRF更加平滑的几何重建结果。此类方法都是基于光度一致性原理,因而难以处理弱纹理区域,在室内场景的重建质量很差。
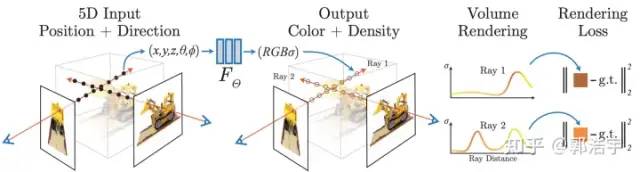
NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis
1.3 我们的观察和对问题的解决
为了克服室内场景重建在弱纹理平面区域的歧义性,我们在优化过程中基于曼哈顿假设采取了相应的几何约束。曼哈顿假设是一个被广泛使用的室内场景假设,即室内场景的地面、墙面、天花板通常被对齐在三个互相垂直的主方向,基于此我们对地面、墙面区域设计了对应的几何约束。

曼哈顿假设示意图
2. 论文方法
2.1 方法概述
论文使用神经隐式表示建模场景的几何、外观和语义,并从多视角图像优化该表示。具体步骤为:
1)使用可微分体积渲染技术,根据输入图像优化几何、外观。
2)预测墙面、地面的语义分割,并基于曼哈顿假设对这些区域采用相应的几何约束。
3)为了提升对语义分割不准确性的鲁棒性,我们提出联合优化策略来同时优化几何和语义,从而实现更高质量的重建结果。

2.2 基于SDF的体积渲染
为了采用体积渲染技术,我们首先将有向距离场转换为体积密度:

2.3 几何约束
我们首先使用DeepLabV3+ [6] 在图像空间分割地面、墙面区域。对于地面区域的每个像素,我们首先做体积渲染得到对应的表面点,通过计算有向距离场在该处的梯度得到法向方向,设计损失函数约束其法向竖直向上:

2.4 联合优化
几何约束在语义分割准确的区域可以起到很好的效果,但网络预测的语义分割在部分区域可能是不准确的,这会影响重建结果。如下图所示,由于语义分割不准确,导致加上几何约束之后重建结果变得更加糟糕。

为了克服这个问题,我们在3D空间中学习语义场。我们使用体积渲染技术将语义渲染到图像空间,并通过softmax归一化得到每个像素属于地面、墙面区域的概率,我们利用这个概率来加权几何约束:
�joint=∑�∈��^�(�)��(�)+∑�∈��^�(�)��(�)
同时,为了避免trivial solution(属于地面、墙面的概率被降为0),我们同时也用2D语义分割网络的预测计算交叉熵作为监督:
��=−∑�∈�∑�∈{�,�,�}��(�)log�^�(�)
3. 实验分析
3.1 Ablation studies
通过定性、定量的实验结果,我们发现使用体积约束能够提升在平面区域的重建效果,但也会由于语义分割的不准确性导致一些非平面区域的重建变差,通过使用我们提出的联合优化策略,可以全面地提升重建结果。
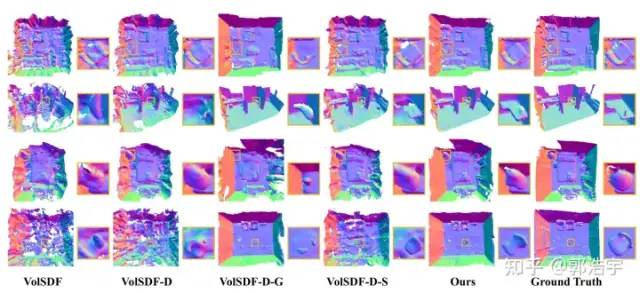
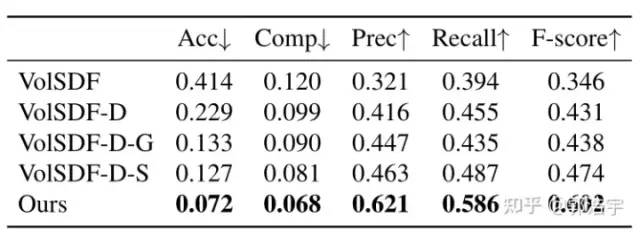
3.2 与SOTA方法的对比
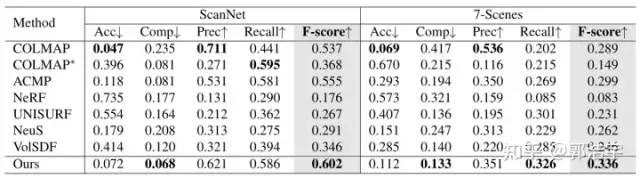
我们在ScanNet和7-Scenes数据集上进行了和之前MVS方法、基于volume rendering的方法的对比,数值结果大幅领先于之前的方法。

审核编辑 :李倩






 关注微信
关注微信