时间:2023-02-10 15:02
人气:
作者:admin
❞
(1)多类别图像分类
(2)细粒度图像分类
(3)多标签图像分类
(4)弱监督与无监督图像分类
(5)零样本图像分类

多类别图像分类在不同物种的层次上识别,往往具有较大的类间方差,而类内则具有较小的类内误差。

细粒度图像分类具有更加相似的外观和特征,导致数据间的类内差异较大,分类难度也更高。

实例级分类可以看做是一个识别问题,比如人脸识别。

(1)数据预处理 (2)图像特征 (3)分类模型
分为两种: 手工特征+分类器、从数据自动学习特征
(1) MNIST数据集:
发布于1998年,60000张图,10类,分布均匀,数据集中的”hello world”
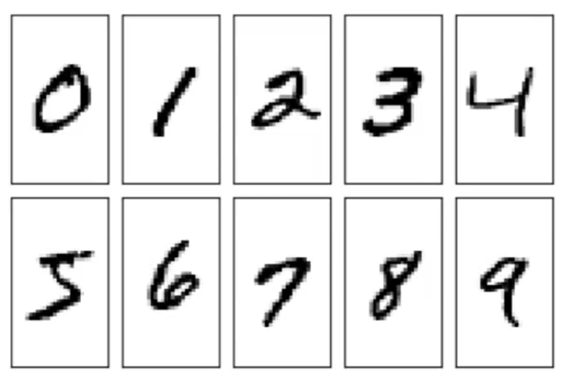
在票据等图像中裁剪出数字,将其放在20 * 20像素的框中,并保持了长宽比率,然后放在28* 28的背景中。
(2) CIFAR10
MNIST的彩色增强版,60000张图片,大小32 * 32,10类,均匀分布,都是真实图片而不是手稿等,图中只有一个主体目标,可以有部分遮挡,但是必须可辨识。

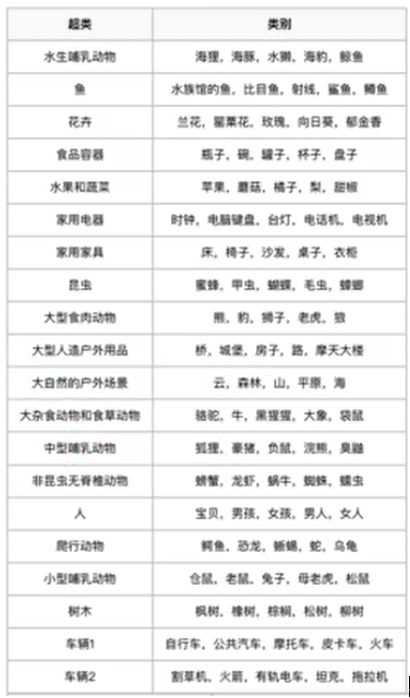
(3) CIFAR100
更加细粒度的CIFAR10,共100类,被分成20个超类。
每小类包含600个图像,其中有500个训练图像和100个测试图像。每个图像都带有一个“精细”标签(它所属的类)和一个粗糙的标签(它所属的超类)

(4) PASCAL
来源于2005-2012的PASCAL Visual Object Classes(VOC项目),20类,来源于图片社交网站flickr,总共9963张图,24640个标注目标。
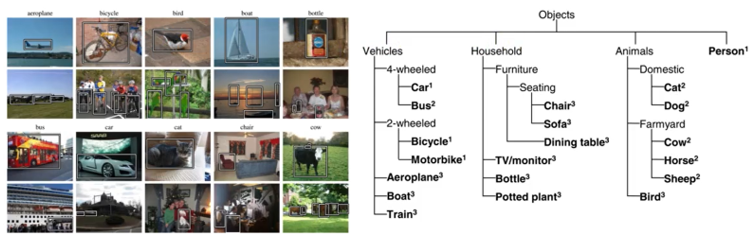
2005年主要用于目标检测,从2007年开始引进了图像分割的标注和人体结构布局的标注,2010年开始引进了行为分类标注。

(5)ImageNet数据集
包含21841个类别,14197122张图片,百万标注框

(1)正负样本
计标签为正样本,分类为正样本的数目为True Positive,简称TP,标签为正样本,分类为负样本的数目为「False Negative」,简称FN,标签为负样本,分类为正样本的数目为「False Positive」,简称FP,标签为负样本,分类为负样本的数目为「True Negative」,简称TN。

(2)精确率、召回率、F1值
精度(查准率): 被判定为正样本的测试样本中,真正的正样本所占的比例
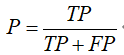
召回率(查全率): 被判定为正样本的正样本占全部正样本的比例
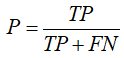
F1-score是综合考虑了精度与召回率,其值越大模型越好。
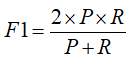
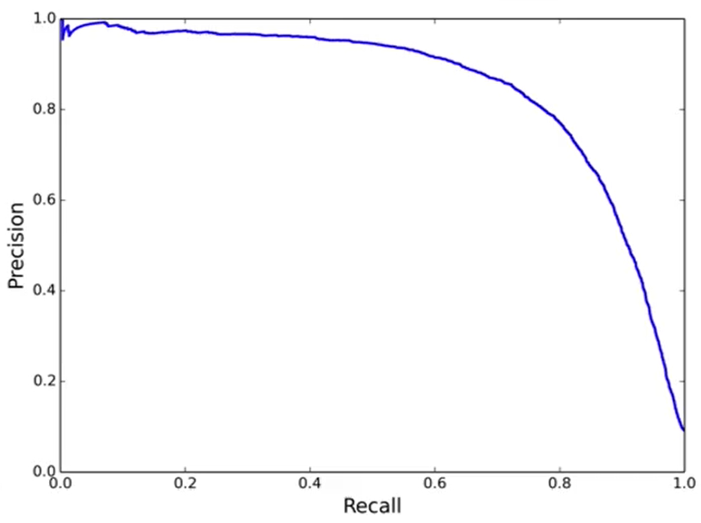
(3)PR曲线
精度与召回率是一对相互矛盾的指标,召回率增加,精度下降,曲线与坐标值面积越大,性能越好,对正负样本不均衡敏感。
(4)ROC曲线与AUC
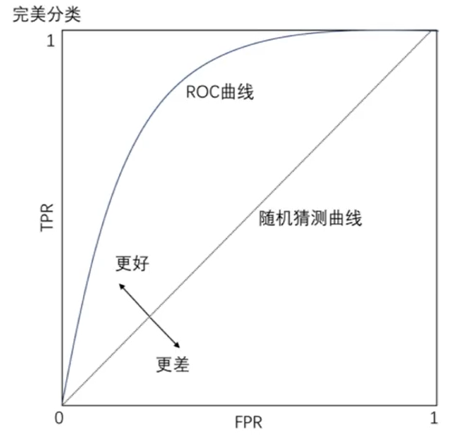
横坐标(假阳率)FPR=FP/(FR+TN) 正类中实际负实例占所有负实例的比例。
纵坐标(正阳率) TPR=TP/(TP+FN) 正类中实际正实例占所有正实例的比例。
正负样本的分布变化,ROC曲线保持不变,对正负样本不均衡问题不敏感。
AUC(Area Under Curve): ROC曲线下的面积,表示随机挑选一个正样本以及一个负样本,分类器会对正样本给出的预测值高于负样本的概率。
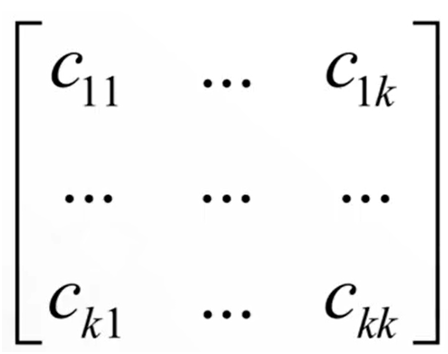
(5)混淆矩阵
多矩阵分类模型各个类别之间的分类情况。
对于k分类问题,混淆矩阵为k*k的矩阵,元素Cij表示第i类样本被分类器判定为第j类的数量。
主对角线的元素之和为正确分类的样本数,其他位置元素之和为错误分类的样本数。对角线之和值越大,正确率越高。
混淆矩阵可以很清晰的反映出各类别之间的错分概率,越好的分类器对角线上的值更大。
(6)0-1损失
只看分类的对错,当标签与与类别相等时,loss为0,否则为1。
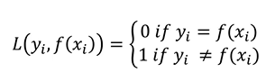
这个是真实的优化目标,但是无法求导和优化,只有理论意义。
(7)熵与交叉熵(cross entropy)
熵表示热力学系统的无序程序,在信息学中用于表示信息多少,不确定性越大,概率越低,则信息越多,熵越高。
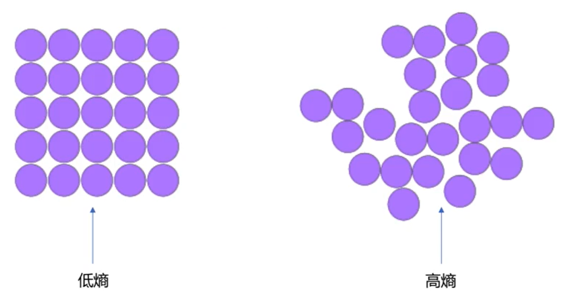
熵是概率的单调递减的函数。

(8)KL散度
用于估计两个分布p和q的相似性
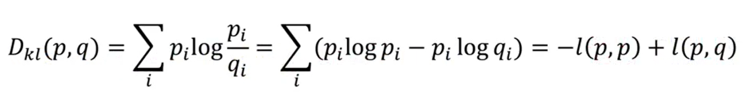
如果p是一个已知的分布(标签),则-l(p,p)是一个常数,此时KL散度与交叉熵l(p,q)只有一个常数的差异。
KL散度的特性是大于等于0,当且仅当两个分布完全相同时等于0。
审核编辑 :李倩
上一篇:网络安全工作需要具备的10种能力






 关注微信
关注微信