时间:2023-02-13 13:44
人气:
作者:admin
研究动机
传统的多模态预训练方法通常需要"大数据"+"大模型"的组合来同时学习视觉+语言的联合特征。但是关注如何利用视觉+语言数据提升视觉任务(多模态->单模态)上性能的工作并不多。本文旨在针对上述问题提出一种简单高效的方法。
在这篇文章中,以医疗影像上的特征学习为例,我们提出对图像+文本同时进行掩码建模(即Masked Record Modeling,Record={Image,Text})可以更好地学习视觉特征。该方法具有以下优点:
简单。仅通过特征相加就可以实现多模态信息的融合。此处亦可进一步挖掘,比如引入更高效的融合策略或者扩展到其它领域。
高效。在近30w的数据集上,在4张NVIDIA 3080Ti上完成预训练仅需要1天半左右的时间。
性能强。在微调阶段,在特定数据集上,使用1%的标记数据可以接近100%标记数据的性能。
方法(一句话总结)
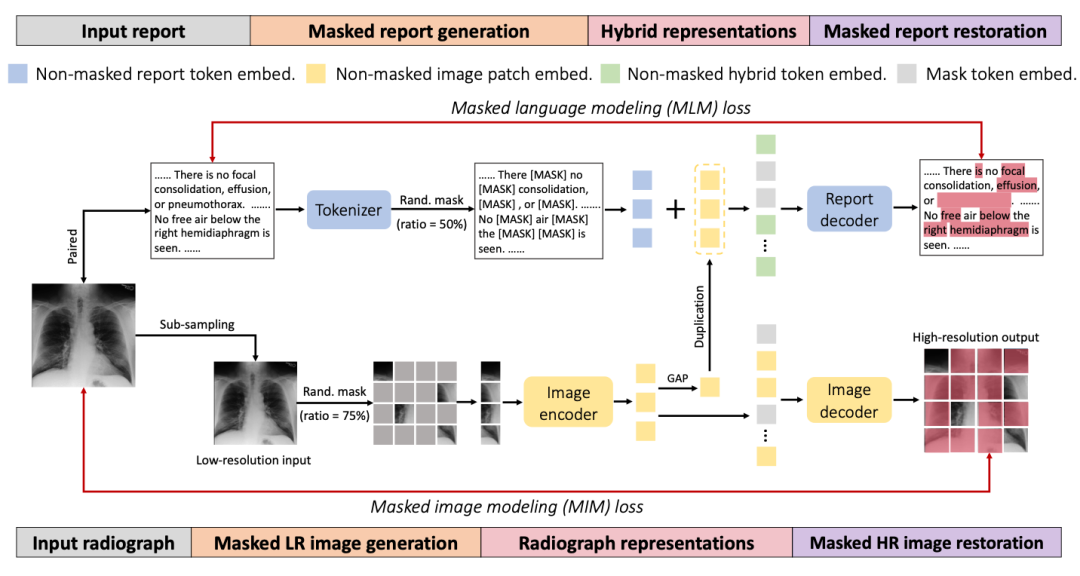
如上图所示,我们提出的训练策略是比较直观的,主要包含三步:
随机Mask一部分输入的图像和文本
使用加法融合过后的图像+文本的特征重建文本
使用图像的特征重建图像。
性能
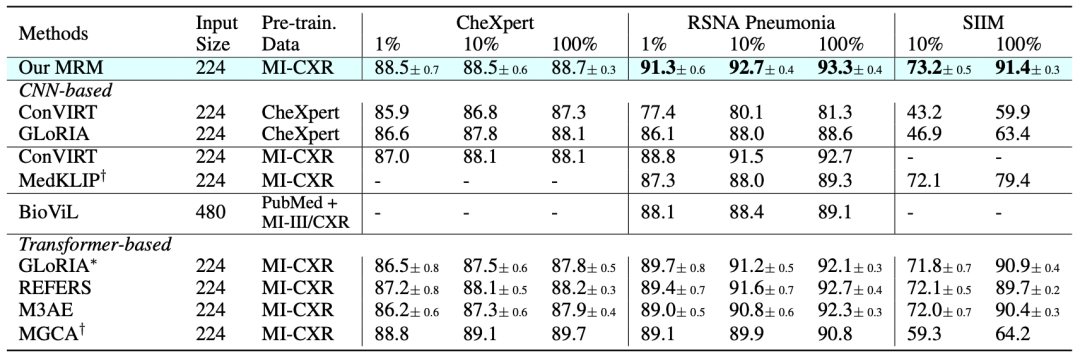
如上图所示,我们全面对比了现有的相关方法和模型在各类微调任务上的性能。
在CheXpert上,我们以1%的有标记数据接近使用100%有标记数据的性能。
在RSNA Pneumonia和SIIM (分割)上,我们以较大幅度超过了之前最先进的方法。
审核编辑 :李倩






 关注微信
关注微信